What's special in RetinaNet?
RetinaNet is a single-stage object detector proposed in the paper Focal Loss for Dense Object Detection by Tsung-Yi Lin, Priya Goyal, et al. In addition to having faster processing speed, it offers higher accuracy in small object detection compared to YOLO and even Single Shot Detector (SSD) [2], thanks to Feature Pyramid Network (FPN) (Fig. 1) and Focal Loss function.
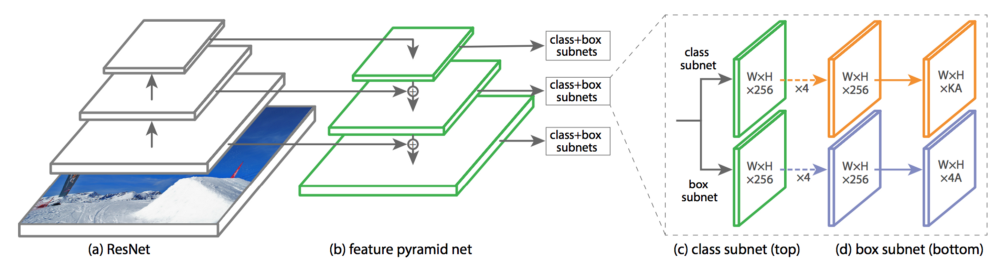
Like other object detectors, RetinaNet is comprised of a backbone model (in this example it's ResNet50) to extract features. As it goes through the convolution layers, the features become increasingly higher level abstractions (SSD uses the features from this downsampling path). Unlike most other object detectors, there's also an upsampling/upconvolution path in the FPN, and it has skipped connections with the backbone features. In essence, this is a U-Net! It improves upon SSD by merging high resolution features together with finer semantic abstractions from the downsampling path. I can't help but notice that skipped connection design has been dominating many recent DL developments (e.g., DenseNet, Super Resolution GAN).
Each of the pyramid feature maps is attached to two subnets, one for classification and one for bounding box regression. Within a task, for example classification, the subnet parameters are shared across the pyramid levels, but the parameters for classification and bbox regression are NOT shared, and each pyramid level will have its own prediction to derive the final prediction. In contrast with Region Proposal Network (RPN), the task subnets are independent from each other.
Finally, focal loss function is simply a modified form of Cross Entropy loss function. It gives less weight
to the loss value
of well trained class (i.e., background), while giving more weight to under-represented, poorly trained class to
help the model 'learn' more efficiently [4].
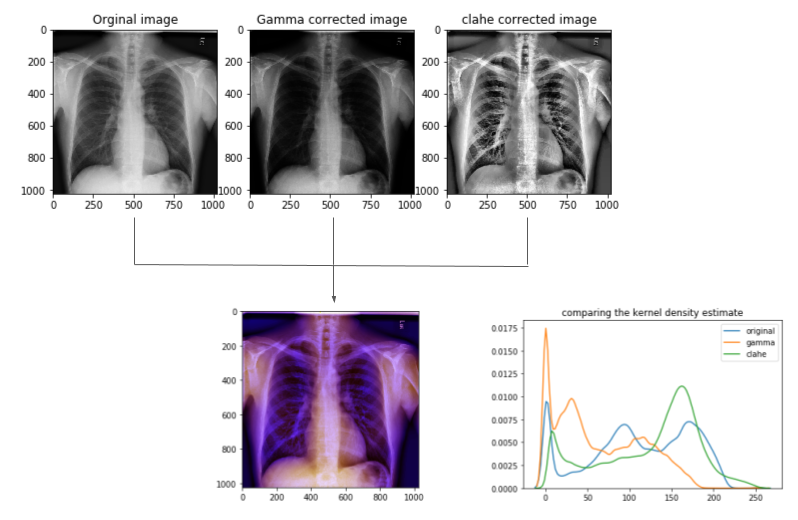
Data Preprocessing
The size of the original dicom image is 1024x1024, which is too expensive for most deep learning models. Another issue is that the RetinaNet model takes 3-channel pixel array (i.e., RGB). So in preprocessing the data, several steps take place. Fig.3 shows an example of the image prepocesing.
- Apply gamma correction[5] and CLAHE (Contrast Limited Adaptive Histogram Equilization) to the image separately.
- Stack the two contrasted images onto the original image to have a 3-channel numpy array suitable for the model.
- Resize the image to 256X256, save them in the proper directory.
- Based on the resize factor, adjust bounding box coordinates in the annotation .csv file.
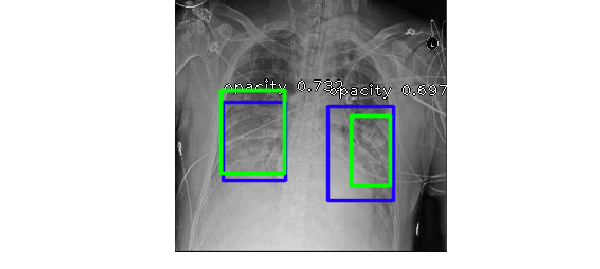
Model Performance (No meta data vs. Meta data)
Following the documentation on Fizyr's git repo, it was very straightforward to train RetinaNet until the losses plateau. After looking at some validation inference by this model (RetinaNet50_1), I notice that it's very sensitive to the confidence score threshold, and it ended up capturing more opacity (true positive) at a lower threshold value. The model at this point also struggled to predict bounding box for smaller opaque regions, that means it had higher number of false negatives, especially in radiographs of smaller stature patients such as children.
After seeing this trend, I wanted to incorporate the available meta data, age and gender, with the correpsonding image to help the model learn better. One crude way to do this is by padding the input pixel array with a vector for age and another vector for values mapped to the gender variable. And a new RetinaNet model (RetinaNet50_2) was trained on these data, Fig.4 shows an example of how the two models perform.
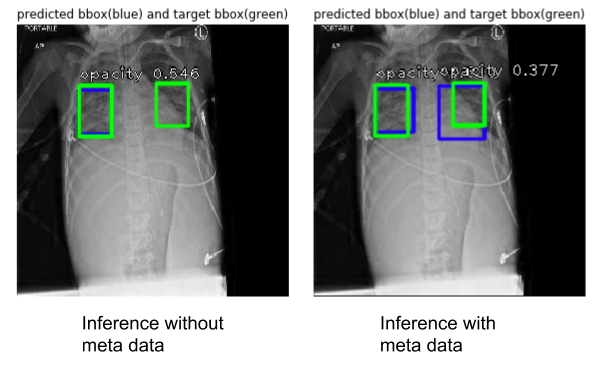
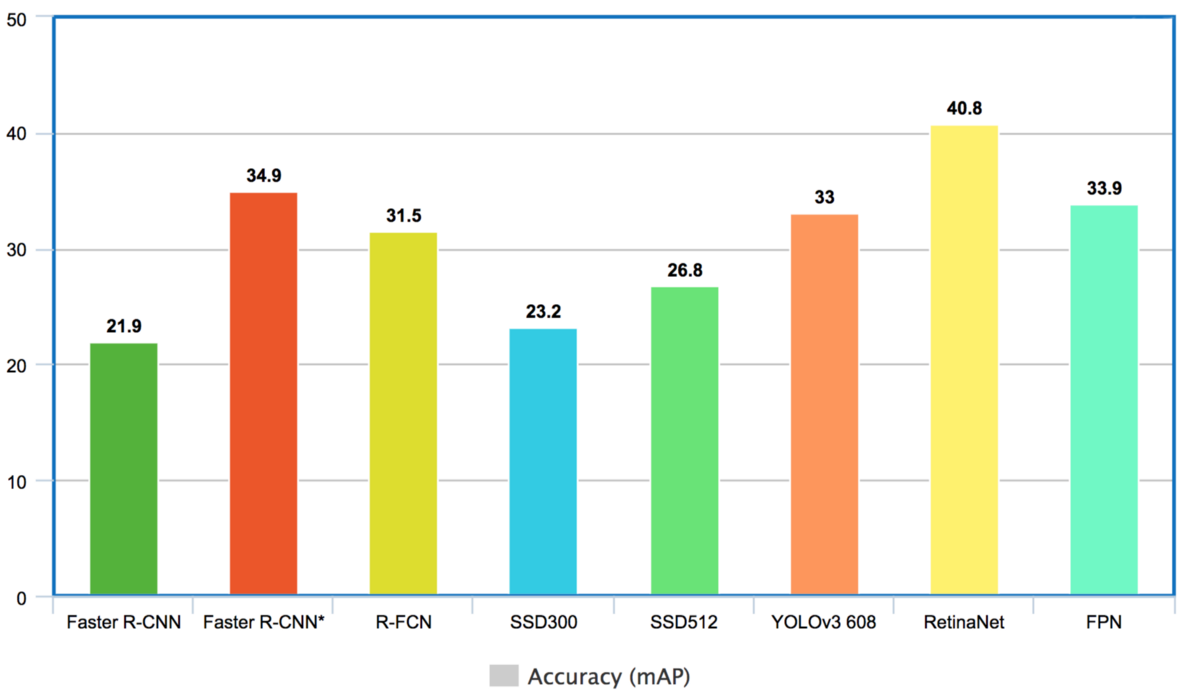
After training, evaluation was done for the two models (see Table 1). mAP is a standard metric for object detection task, it calculates the average pixel-wise precision in each image and takes the mean across all images in the dataset. On the other hand, precision and recall values were calculated based on whether or not it correctly generated a bounding box (sometimes there's two bounding boxes in one radiograph), but it's not a pixel-wise calculation for the sake of simple comparison. High precision means lower false positives, and high recall means lower false negatives.
| Model Name | Precision | Recall | mAP (validation) |
|---|---|---|---|
| RetinaNet50_1 | 0.753 | 0.619 | 0.427 |
| RetinaNet50_2 | 0.656 | 0.736 | 0.464 |
The mAP values don't differ significantly for the two models, however it's clear that there's a trade off between false negative and false positive. With meta data padding, RetinaNet does seem to do a better job in capturing opaque regions (higher recall). One idea for potential improvement is to concatenate the meta data with the feature map within the model. It is possible that these two models can work together to identify prediction outputs that are likely to be false negative or false positive.
REFERENCES
[1]RSNA Pneumonia Detection Challenge, https://www.kaggle.com/c/rsna-pneumonia-detection-challenge
[2]Hui, J. 2018, Medium.com Object detection: speed and accuracy comparison (Faster R-CNN, R-FCN, SSD, FPN, RetinaNet and YOLOv3).
[3]Hui, J. 2018, Medium.com What do we learn from single shot object detectors (SSD, YOLOv3), FPN & Focal loss (RetinaNet)?.
[4]Lin T., Goyal, P., et al, Feb 2018, Focal Loss for Dense Object Detection, ArVix:1708.02002
[5]Ikhsan I.A., Hussain A.,et al, Mar 2014, An analysis of x-ray image enhancement methods for vertebral bone segmentation, 2014 IEEE 10th International Colloquium on Signal Processing and its Applications