
"Art is not what you see, but what you make others see." - Edgar Degas
Beyond Photoshop style transfer
One of the first Deep Learning models used to affect visual content is the Style Transfer algorithm (which is now a feature of Photoshop). It maps the style from one image to another image while maintaining the content of the second image. It works by fine tuning specific feature maps of a pre-trained convolutional model to induce stylistic change.

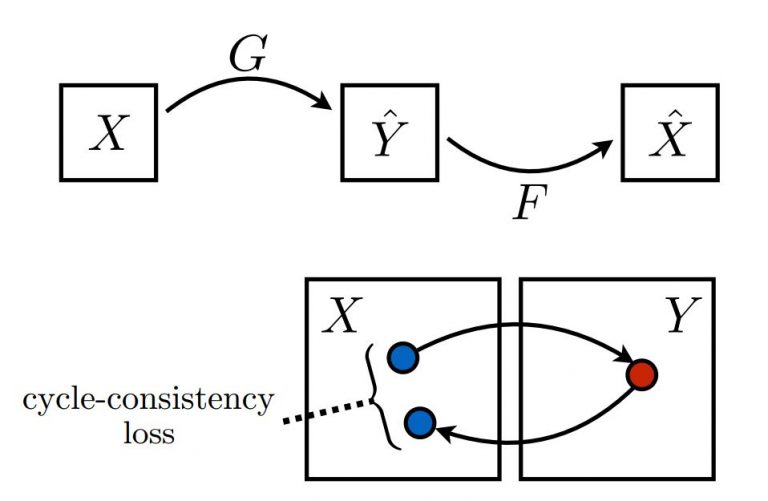
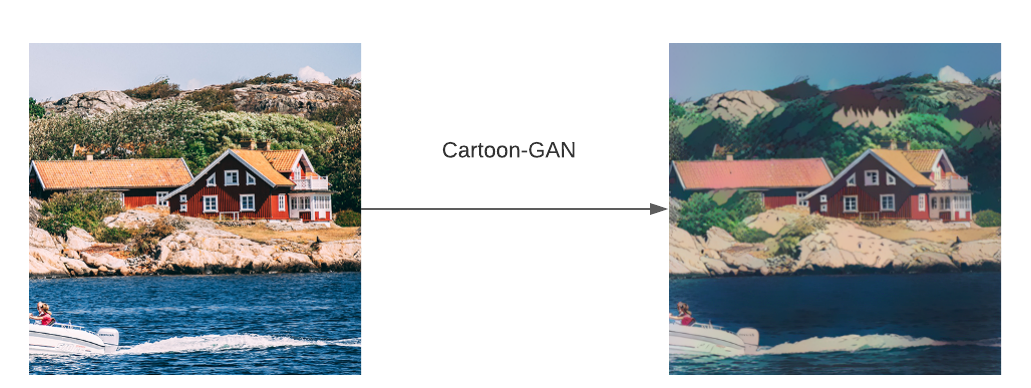
The limitation with style transfer is it requires a one-to-one pairing between the two images, and it only transfers the style of one image, which doesn't fully encapsulate the overall style of a particular artist or genre. An alternative to that is cycleGAN, which trains the network to translate style using two sets of training images representing different genres. This model runs on something called `full translation cycle'. For each cycle, the Generator G produces Ŷ to try to fool the discriminator D_Y, and generator F produces X̂ to try to fool the discriminator D_x. The optimization is done using cycle-consistency loss, where the generated image Ŷ is translated to the counterpart image X̂, which is compared to the ground truth X to quantify the loss metric and improve the generator network.
Generating new content
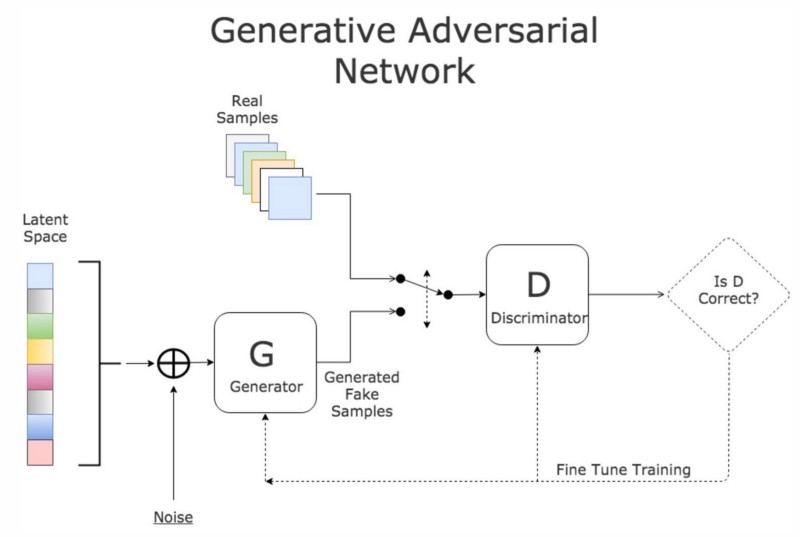
To make things more interesting enter Generative Adversarial Network(GAN), a deep learning model created by Ian Goodfellow in 2014 that is a generative model for unsupervised learning (but uses a supervised learning loss function). The system tries to learn the salient features of the training image dataset using convolutional neural networks. It is composed of a discriminator and a generator (each being a Deep Convolutional Neural Net), where the generator attempts to mimic the data distribution of the training data so it can fool the discriminator and pass its generated output as a "real" image. Much like counterfeit bills. The training is adversarial in that it alternates between the discriminator and generator, the generator is held constant during the discriminator training and vice versa, ensuring that both neural networks are learning at the same pace.
After training the two models, the generator can take a latent 1-D vector that is randomly generated and generate something novel in the genre of the training images.
But there is a downside to Deep Convolutional GAN.
Take a look at the DCGAN generated images floating around, and you'll notice that they are usually 64x64 or 128x128 at best. This is because training a vanilla DCGAN to higher resolution leads to a common problem called 'mode collapse': a phenonmenon where the generator over-optimizes for the discriminator by producing the same subset of output that succeeds in fooling the discriminator which is stuck in local minimum. With mode collapse, it will generate repeated patterns that lack expressive diversity again and again.
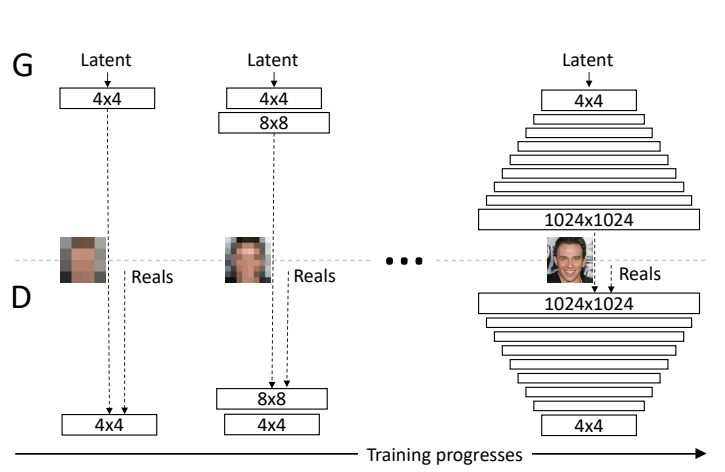
In an attempt to overcome this problem, the researchers at NVIDIA came up with the idea of Progessive GAN(PGAN) to avoid 'shocking' the model network into mode collapse at high resolution[2]. The PGAN model starts training from low resolution (4x4) and gradually trains to higher resolution (1024x1024) to stabilize and speed up the training process. The intuition is that it's easier for the model to learn the big shape and edges first before progressing to learn the finer details of the composition. In fact, this underlying concept is a lot like how artists approach oil painting - first block in the big shapes plus the highest and lowest tonal values, then gradually add the smaller details and mid-range values to complete the painting. Figure 5 below gives a glimpse of how the image pixels evolve in a training I did with an open-source PGAN model written by Animesh Karenewar[3].
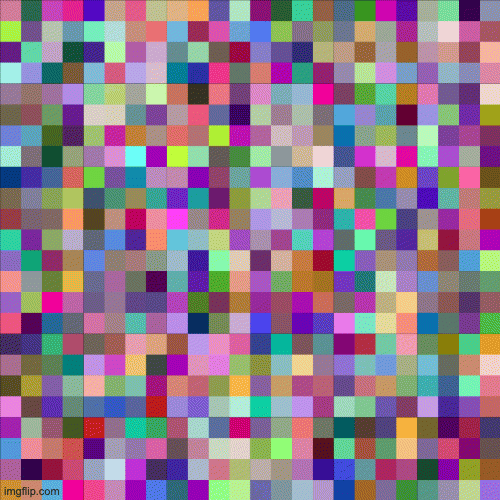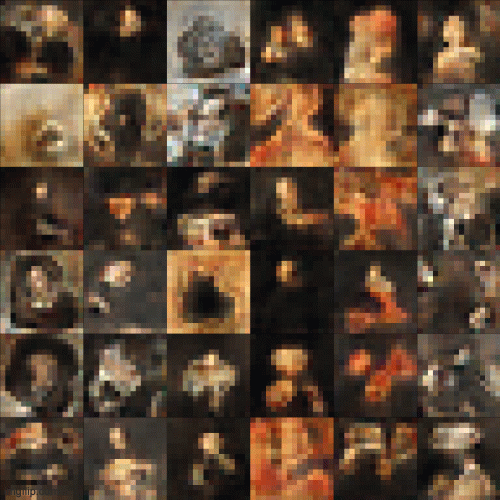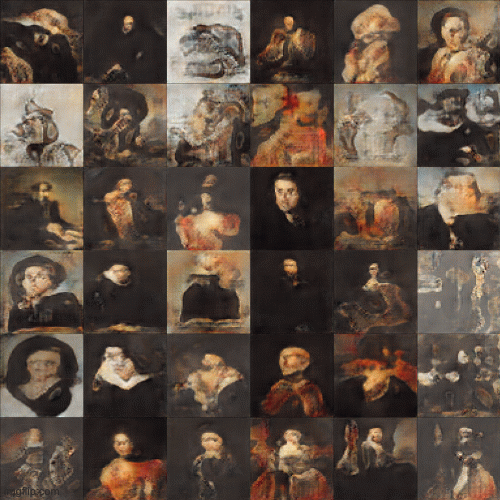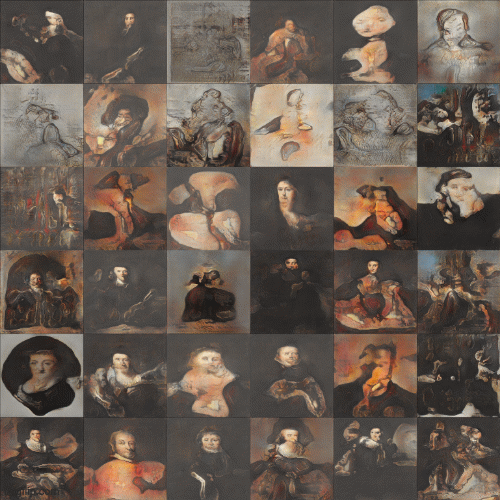
Natural language as art
A new approach to AI Art has recently caught people's attention with the release of DALL-E(a portmanteau of Dalí and Pixar’s WALL·E) from OpenAI. It is essentially an instance of GPT-3 (with 12 billion parameters) that learned how to map the input text to an output of pixel arrays via Transformer, and the output image is ranked by CLIP to obtain the top 32 results. All of the images generated by DALL-E are novel because they are synthesized from the concepts of the input prompt.
The ability to capture various contexts and blending them means that DALL-E can come up with new designs from seemingly unrelated concepts. I tried it out and it got pretty crafty designing lamps inspired by butterfly-wings, and it actually resembles something I'd buy!
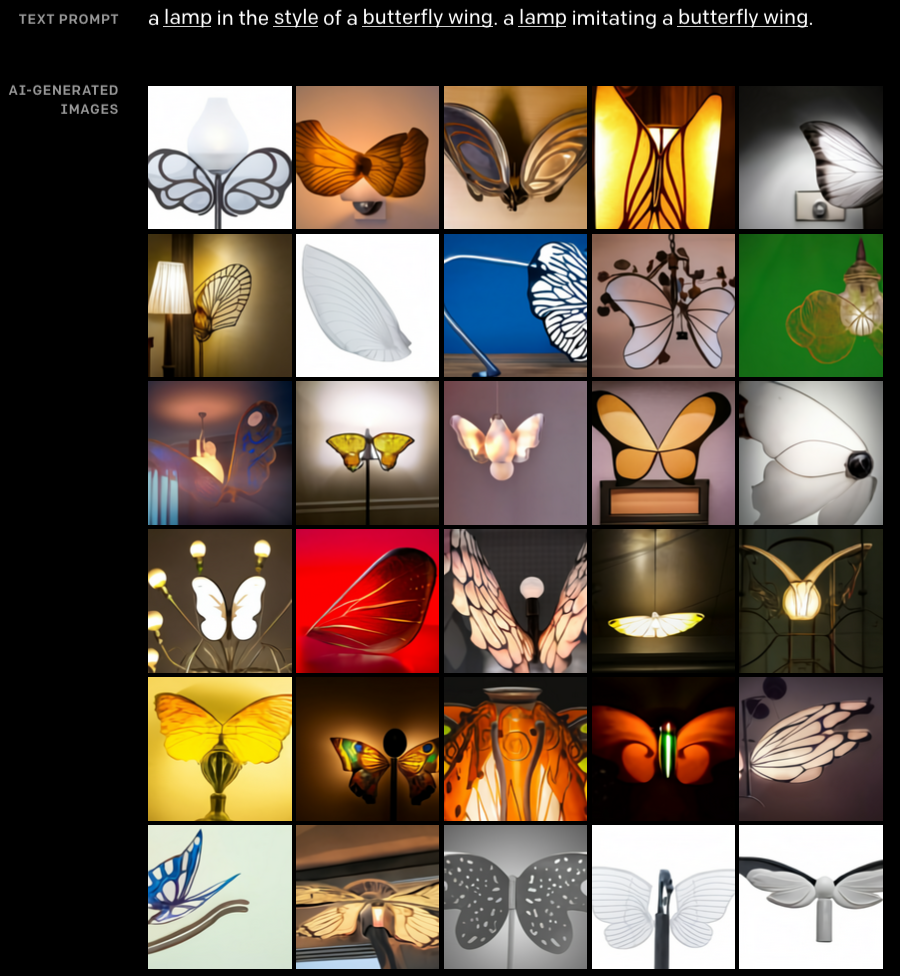
For a more whimsical interpretation, check out the armchair in the style of a strawberry.🍓
Is it really art?
Before the headline-grabbing auction of the GAN art 'Portrait of Edmond Belamy' by Obvious, London-based artist Memo Akten was among the first few artists to sell AI-generated art, the most notable being the piece All watched over by machines of loving grace at a Google charity auction in 2016. It was based on a satellite image of GCHQ reimagined through the lens of Google DeepDream(it surprisingly didn't look gauche).
While a GAN model learns the artistic style and content and is able to produce art on its own, it still requires the involvement of humans in the form of data collection and training. It acts as a medium because unlike human it cannot be inspired to come up with new styles or artistic interpretation in the same vein that Jackson Pollock reinvented the 'drip technique'.
The elephant in the room is the question of ownership - specifically who owns the training codes and the output. The general consensus is that the person who curates the data set and trains the model to generate the output has rights to those art work[4], with the assumption that they used training images that are public domain. If the training image is copyrighted then it is best practice to ask for the permission of the copyright holder. However, technically speaking, AI Art modeling can be covered under the Fair Use principle. According to Creative Future, "artistic works that are transformed in some way by another artist to comment on the original with new expression or meaning are often considered to be fair uses and do not lead to litigation." [5]
Ultimately, any artistic creativity is expressed by the human artist who designed the code and/or trained the model, with influences from the artists behind the training data. And the evolution of art can be aptly summarized by this quote:
“Learn the rules like a pro, so you can break them like an artist.” - Pablo Picasso
While AI Art is carving out a niche within the art bubble, I'm a firm believer that conventional artists would not be replaced by AI (at least with the current models), because human sensibilities and the whim to deviate from the norm are not something any current algorithm can emulate.
REFERENCES
[1]F Anderssen, S Arvidsson, Generative Adversarial Networks for photo to Hayao Miyazaki style cartoons, arXiv preprint arXiv:2005.07702, 2020
[2]T Karras, T Aila, S Laine, J Lehtinen, Progressive growing of gans for improved quality, stability, and variation, arXiv preprint arXiv:1710.10196, 2017
[3]A Karenewar, pro_gan_pytorch, https://github.com/akanimax/pro_gan_pytorch
[4]S Gaskin, When Art Created by Artificial Intelligence Sells, Who Gets Paid?,https://www.artsy.net/article/artsy-editorial-art-created-artificial-intelligence-sells-paid
[5]The Fair Use Confusion Game, https://www.creativefuture.org/why-this-matters/fairuse/